What’s new in Elasticsearch 3.0?
Yes, you read that well, Elasticsearch development is so fast that there’s already a lot of things to say about Elasticsearch 3.0, even if the 2.0 is only 3/4 months old1.
Last year’s Elastic{On} Parisfr was awesome and home for announcements, especially about a new query profiler I’m quite excited about. Some of this might land in 2.2 too, but we will have to wait and see.
Be aware that nothing of what I am talking about here has been released so far, and everything could change. You can also expect announcements at Elastic{ON}16 later this month.

An Elasticsearch developer building new features at light speed.
Section intitulée query-profilerQuery Profiler
Definitively going in 2.2 (Edit: it has!), a new Profile API has been added to Elasticsearch. It exposes detailed timing of query execution, allowing to understand why search is slow and improve your queries.
Usage is simple, you add a profile boolean in your DSL and a new profile key will appear in the search results, like the explain flag already does:
GET /_search
{
"profile": true,
"query" : {
"match" : { "title" : "jolicode" }
}
}
Each shard of each index is running the query, so the profiling is done on all of them. Response looks like this:
{
"profile": {
"shards": [
{
"id": "[nodeID][indexName][shardID]",
"searches": [
{
"query": [...],
"rewrite_time": 275020,
"collector": [...]
}
]
}
]
}
}
searches contains those node:
-
query: detailed timing of the query tree executed by Lucene; -
collector: high-level execution details of Lucene; -
rewrite_time: the cumulative query rewrite time in nanoseconds.
Responses from the profiler are not complete yet (they miss aggregations, highlights…) but are already very verbose. I didn’t find any plugin to display them in a cool way neither, and I hope someone is going to do it!
Section intitulée new-scripting-languageNew scripting language
In my Elasticsearch formation, I delay the scripting part for the last hour of the last day – it’s perfect because everyone think Elasticsearch is awesome at this point, and I can crush their dreams by asking them to debug a one-liner!
From MVEL to Groovy, scripting in Elasticsearch is a mess to build and debug. You can never tell what’s available, or why both _doc and doc are valid variables, and sand-boxing hasn’t been easy.
This PR does not resolve debug difficulties, but add a new sand-boxed language in Core called Painless (first name was PlanA), much more powerful than the actual Expression and Mustache. It’s supposed to be:
- fast to learn, similar to the Java syntax;
- based on a subset of groovy-like scripts;
- it use ASM to convert the script into Java byte code;
- infinite loop free, with an instructions counter.
It’s looking good for the future of scripts, as Painless is going to be massively adopted and it opens the door to debug tools, document sandbox… To be continued!
Section intitulée more-consistent-settingsMore consistent settings
You know it, settings can be messy. Some can be dynamically set, some can only be set in config/elasticsearch.yml but they do not appear in the _settings API… It’s always hard to tell “what are all the current setting for this index”, or what settings are specific to an index or not.
PR 16054 provides a new settings infrastructure and:
- better validation of index settings upon index creation, template creation and index settings update, no more wrong setting requests, they will be rejected;
- settings update are now transactional;
- validation of node level settings upon node start-up;
- ability to reset a setting to the default by passing
null; - and finally, ability to list all the settings directly via the API.
Section intitulée new-task-management-apiNew task management API
Elasticsearch can spawn some long running tasks, from doing a merge to running a big query with deep paging. At the moment, we have no clue of what a cluster is doing, and this API is here to help.
GET /_tasks
GET /_tasks/nodeId1,nodeId2
GET /_tasks/nodeId1,nodeId2/cluster:*
Response should look like this:
{
"nodes" : {
"nodeId1" : {
"name" : "Thor",
"transport_address" : "127.0.0.1:9300",
"host" : "127.0.0.1",
"ip" : "127.0.0.1:9300",
"tasks" : [ {
"node" : "nodeId1",
"id" : 105,
"type" : "transport",
"action" : "cluster:monitor/nodes/tasks"
}, ...]
}
}
}
Work on this feature is not finished yet, but we should also be able to communicate with running stuffs, so an admin could kill a bad query on the fly.
Section intitulée new-reindex-apiNew reindex API!
Highly dependent on the task management API, this new endpoint will allow us to reindex without external tools like stream2es. Actually bundled as a plugin, it adds two endpoints:
-
_update_by_query: updates all documents matching a query. Useful when you add a new “multifield” in the mapping and just want to update the index with the_sourcealready in place; -
_reindex: just copies documents from one index to another.POST /_reindex { "source": { "index": "jolicode" }, "dest": { "index": "new_jolicode" } }
At the moment it uses scrolls and bulks, but as a core feature, it could directly play on the file-system in the future. Both methods supports scripts and handle conflicts.
Section intitulée ingest-nodeIngest node
Didn’t saw that one coming: the core team is building a way to filter and enrich documents before they land into an index.
They implemented some common processor like GeoIP, Grok and Date, in Java, that can be reused elsewhere (like in the reindex API, maybe, and later in Logstash). Then, they coupled them with Elasticsearch in order to intercept bulk and index calls.
This will allow us to get rid of logstash in places where we only use it for data enrichment.
To use it, you will have to declare some pipelines, and reference them in your calls to the index and bulk APIs:
PUT _ingest/pipeline/lowercase-all-the-titles
{
"description" : "I don't like caps.",
"processors" : [
{
"lowercase": {
"field": "title"
}
}, // other processors
]
}
PUT /jolicode/articles/1?pipeline=lowercase-all-the-titles
{
"title": "WILL BE LOWERCASED BEFORE INDEXING"
}
There’s a lot of processors and they also added a node.ingest: true parameter, allowing users to control whether or not a node can do such processing.
Section intitulée faster-percolatorFaster percolator
The Percolator has been optimized and is now indexing the queries terms. This means matching queries are faster to find, and some changes are introduced:
- Queries modifications aren’t visible immediately and now needs a refresh;
- Results are now limited to 10 (as search results, the
sizeparameter can be used).
Section intitulée primary-shard-are-quot-persistent-quotPrimary shard are “persistent”
A nice improvement for resilience is about primary shard automatic assignment. A commonly known issue on cluster can happen when two nodes are separated from each others (network failure, etc).
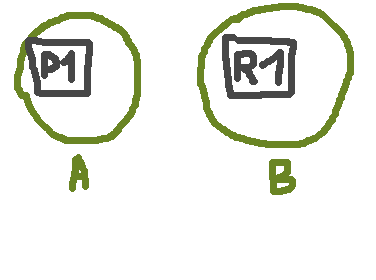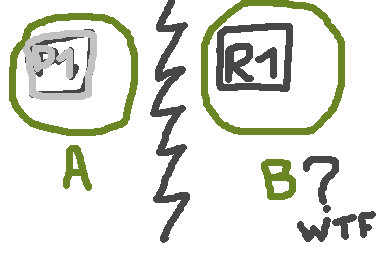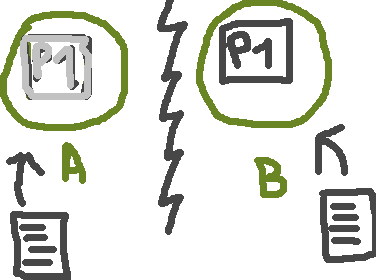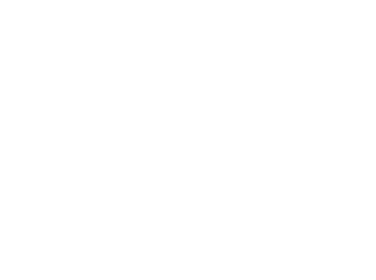
You have P1 on node A and R1 on node B, and one day P1 fails to be readable. R1 becomes the new primary shard and the cluster virtually get two P1, as you can see in the beautiful animation above. We can index documents without issues as B owns a primary.
If B come missing too and A come back, our old P1 is going to be primary again, and documents we put in B are now lost – for good. ES 3.0 now store persist allocation IDs of active shards in cluster state and use them to recover correct shards upon cluster restart or failure.
Section intitulée new-search-cursor-for-pagingNew search cursor for paging
Pagination as you know it (with from and size) costs more and more the deepest you go. That’s why there is an index.max_result_window setting which defaults to 10,000.
When we need to fetch a lot of document we simply rely on the scroll request… But they don’t sort and they have a cost because they do a snapshot of your results. Introducing the search_after parameter!
It allows you to define a live cursor based on the results from the previous page, making deep paging faster and real-time:
GET _search
{
size: "10"
"query": {
"match" : {
"title" : "jolicode"
}
},
"sort": [
{"age": "asc"},
{"_uid": "desc"} // You need some unique key
]
}
As you know, sort fields values are returned in search results. All we have to do is copy the ones from the last result to get our next page:
GET _search
{
"size": 10
"query": {
"match" : {
"title" : "jolicode"
}
},
"search_after": [42, "article#654323"],
"sort": [
{"age": "asc"},
{"_uid": "desc"}
]
}
This is an awesome feature that will also allow us to avoid the “jumping” effect of classic from based search in an heavy indexing environment.
Section intitulée conclusionConclusion
Elasticsearch 2 was about stability and availability. Elasticsearch 3 is clearly about features! I only listed the most obvious but at the time of writing this, master is 4200 commits ahead of the 2.2 branch. There is no official roadmap and that’s too bad because they seem to clearly know where they are going.
As a side note you should know that site plugins are removed and must be moved to Kibana. That’s going to make some noise as there is a huge amount of plugin that may never make this move. The Kibana App API is not fully established yet and the proxy introduces some limitations.
Anyway, congrats to everyone on the core team, you are doing an incredible job as making this software the database I want to work with.
Elasticsearch 2.0 release was in October 2015. ↩
Commentaires et discussions
Nos formations sur ce sujet
Notre expertise est aussi disponible sous forme de formations professionnelles !
Elasticsearch
Indexation et recherche avancée, scalable et rapide avec Elasticsearch
Ces clients ont profité de notre expertise

Qobuz nous a également sollicité pour la refonte de son moteur de recherche pour employer Elasticsearch, dont JoliCode a une très forte expertise. L’indexation en temps réel et les problématique de droits sur les contenus musicaux ont été les principales difficultés rencontrées. Au final, l’emploi d’ElasticSearch et notre approche technique ont permis…

Dans le cadre d’une refonte complète de son architecture Web, Expertissim a sollicité l’expertise de JoliCode afin de tenir les délais et le niveau de qualité attendus. Le domaine métier d’Expertissim n’est pas trivial : les spécificités du marché de l’art apportent une logique métier bien particulière et un processus complexe. La plateforme propose…
![]()
Dans le cadre du renouveau de sa stratégie digitale, Orpi France a fait appel à JoliCode afin de diriger la refonte du site Web orpi.com et l’intégration de nombreux nouveaux services. Pour effectuer cette migration, nous nous sommes appuyés sur une architecture en microservices à l’aide de PHP, Symfony, RabbitMQ, Elasticsearch et Docker.